문자를 찾는 방법에대해 알아보겠습니다.
-
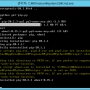
find(찾을문자, 찾기시작할위치)
>>> s = '가나다라 마바사아 자차카타 파하'
>>> s.find('마')
5
>>> s.find('가')
0
>>> s.find('가',5)
-1
find는 문자열중에 특정문자를 찾고 위치를 반환해준다, 없을경우 -1을 리턴
-
startswith(시작하는문자, 시작지점)
>>> s = '가나다라 마바사아 자차카타 파하'
>>> s.startswith('가')
True
>>> s.startswith('마')
False
>>> s.startswith('마',s.find('마')) #find는 '마' 의 시작지점을 알려줌 : 5
True
>>> s.startswith('마',1)
False
startswith는 문자열이 특정문자로 시작하는지 여부를 알려준다
true나 false 를 반환
두번째 인자를 넣음으로써 찾기시작할 지점을 정할수있다.
-
endswith(끝나는문자, 문자열의시작, 문자열의끝)
>>> s = '가나다라 마바사아 자차카타 파하'
>>> s.endswith('마')
False
>>> s.endswith('하')
True
>>> s.endswith('마',0,10)
False
>>> s.endswith('마',0,6)
True
endswith는 문자열이 특정문자로 끝나는지 여부를 알려준다.
true나 false를 반환
두번째인자로 문자열의 시작과 세번째인자로 문자열의 끝을 지정할 수 있다.
지정한 검색 문자를 모두 찾고 싶은 경우도 있습니다.
모두 찾기 예제
str = 'abcabcabc'
target = 'b'
index = -1
while True:
index = str.find(target, index + 1)
if index == -1:
break
print('start=%d' % index)
find에 지정한 문자를 모두 찾아 출력하도록 합니다.
find, find_all
>>> bs . find ( 'title' ) # 태그값을 기준으로 내용 불러오기 (최초 검색 결과만 출력)
<title> test.web </title>
>>> bs. find_all ( 'p' ) # 해당 모든 태그를 불러온다 / [ 리스트 ]
[<p align.......> ......
>>> bs. find_all ( align = "center" ) # 속성값을 기준으로 태그를 불러온다
[ <p align = "center" .....
>>> bs. find_all ( 'p' , limit = 2 ) # 해당 모든 태그 중 2개 까지만
[<p align.......> ......
find(''). find('')
>>> head_tag = bs . find ( 'head' )
>>> head_tag . find ( 'title' ) # head 태그 내부 title 태그의 내용을 불러온다
>>> bs . find ( 'p' , align = "right" ) # p 태그 중 /and/ align = "right" 을 포함한 태그를 불러온다
<p align="right....... >
>>> body_tag = bs . find ( 'body' )
>>> list1 = body_tag. find_all ( ['p','img'] ) # [] 리스트 , 'p' /or/ 'img' 를 포함하는 태그를 불러온다
>>> for tag in list1 :
print ( tag )
< p align....
< img height = "300" ......>
정규식 함수 활용
>>> import re
>>> bs. find_all ( re . compile ("^p") ) # p 글자를 포함하는 태그
>>> bs. find_all ( text = " text contents 1" ) # text contents 1 을 포함하는 태그
>>> bs. find_all ( text = re . compile (" text + ") ) # text 부가 내용 포함하는 태그
>>> bs. find_all ( re . compile ("^p") ) # p라는 글자를 포함하는 태그를 불러온다.
문장으로 가져오기
>>> tags = bs .find ('body') .find_all ('img')
>>> tags . string # string 은 1번에 1문자 씩만 변환가능
' img = 'cowboy.jpg' '
>>> strings = tags . string
>>> for string in strings :
print (string)
>>> body_tag = bs.find('body')
>>> body_tag. get_text() # 모든 문자열을 하나의 문자열로 되돌린다.
' \n text contents1 \n text contents 2 \n tex...... '
>>> body_tag. get_text ( strip = True ) # \n 줄바꿈 기호가 삭제된 채 출력
' text contents1 text contents 2 tex...... '
>>> body_tag. get_text ( '-' , strip = True ) # \n 기호가 '- 로 출력
' text contents1 - text contents 2 - tex...... '