출처 : https://docs.gspread.org/en/latest/advanced.html
gc.open_by_url을 사용하려면 반드시 편집자가 사용할 수 있게 공유자를 추가해야 합니다.
다음 코드로 새 Python 파일을 만듭니다.
import gspread
gc = gspread.oauth()
sh = gc.open("Example spreadsheet")
print(sh.sheet1.get('A1'))
이 코드를 실행하면 인증을 요청하는 브라우저가 실행됩니다. 웹 페이지의 지침을 따르십시오. 완성되면, gspread 상점 옆에있는 config 디렉토리에서 자격 증명 권한 credentials.json을 . 브라우저에서 한 번만 인증하면됩니다. 다음 실행은 저장된 자격 증명을 재사용합니다.
gspread 사용의 예
앱을 아직 승인하지 않은 경우 먼저 인증을 읽어보세요 .
스프레드 시트 열기
Google 문서에 표시되는 제목으로 스프레드 시트를 열 수 있습니다.
sh = gc.open('My poor gym results')
구체적으로 알고 싶다면 키 (스프레드 시트의 URL에서 추출 할 수 있음)를 사용하십시오.
sht1 = gc.open_by_key('0BmgG6nO_6dprdS1MN3d3MkdPa142WFRrdnRRUWl1UFE')
또는 해당 키를 추출하는 것이 너무 게으르다면 전체 스프레드 시트의 URL을 붙여 넣으세요.
sht2 = gc.open_by_url('https://docs.google.com/spreadsheet/ccc?key=0Bm...FE&hl')
스프레드 시트 만들기
create()새 빈 스프레드 시트를 만드는 데 사용 합니다.
sh = gc.create('A new spreadsheet')
스프레드 시트 공유
이메일이 otto@example.com 인 경우 새로 생성 된 스프레드 시트를 자신과 공유 할 수 있습니다.
sh.share('otto@example.com', perm_type='user', role='writer')
share()허용되는 매개 변수의 전체 목록은 문서를 참조하세요 .
워크 시트 선택
인덱스로 워크 시트를 선택합니다. 워크 시트 색인은 0부터 시작합니다.
worksheet = sh.get_worksheet(0)
또는 제목으로 :
worksheet = sh.worksheet("January")
또는 가장 일반적인 경우 : Sheet1 :
모든 워크 시트 목록을 가져 오려면 다음을 수행하십시오.
worksheet_list = sh.worksheets()
워크 시트 생성
worksheet = sh.add_worksheet(title="A worksheet", rows="100", cols="20")
워크 시트 삭제
sh.del_worksheet(worksheet)
셀 값 얻기
A1 표기법 사용 :
val = worksheet.acell('B1').value
또는 행 및 열 좌표 :
val = worksheet.cell(1, 2).value
txt1 = str(entry_0.get()) # entry_0에 문자열 값을 txt1에 저장한다.
cell = worksheet.find(txt1) # 워크시트에서 txt1 값으로 셀 정보를 cel1에 정한다.
#print("찾은 셀위치 R%sC%s" % (cell.row, cell.col))
cell_list = worksheet.findall(txt1) #워크시트에서 txt1로 검색한 모든 결과값을 cell_list에 저장한다.
print(cell_list) #cell_list를 출력한다.
value = cell.value #cel1값을 value에 저장한다.
print(value) #value값을 저장한다.
row_number = cell.row #cel1의 row 위치값을 row_number에 저장한다.
print(row_number) #row_number를 출력한다.
column_number = cell.col #cel1의 col 위치값을 colnum_number에 저장한다.
print(column_number) #column_number를 출력한다.
vv = worksheet.cell(cell.row, cell.col+3).value #워크시트의 cel1의 행, 열에 있는 결과값을 vv에 저장한다.
print(vv) #vv값을 출력한다.
업데이트 / 삽입
업데이트
해당 키의 값을 업데이트 하고자 한다면?
worksheet.update('B1', '<Value>')
위와같이 첫번째 인자에는 행열의 위치를 지정하는데 나 같은 경우엔 소스코드에서 딕셔너리로 열에 대한 정보를 만들어 놓았다.
col = {
'key': 'A',
'value': 'B'
}
worksheet.update(col['value'] + str(t.row), '<Value>')
멀티라인? 다중배열구조로 한꺼번에 많은 데이터 업데이트 시키기
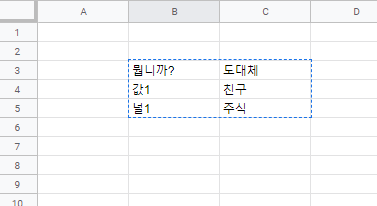
worksheet.update('B3:C4', [['값1','친구'],["널1",'주식']]) # 값과 친구는 B, C열의 3번행에 / 널1과 주식은 B, C 열의 4번행에 들어갑니다.
결과>>
삽입
worksheet.insert_row(['<Value>', '<Value>'])
insert_row 메서드를 사용하면 0번 행에 값을 추가한다. 0번 행은 구분 값으로 사용하려던터라 마지막 행에 넣는 방법을 찾고자 하였으나 구분값을 굳이 사용하지 않는다면 활용성이 높을 것으로 보인다.
여하튼 값을 찾을 때 값이 없으면 새로운 행을 삽입하는 코드는 아래처럼 작성할 수 있겠다.
find_row = None
try:
find_row = worksheet.find("<Value>")
except:
worksheet.insert_row(['<Value>', '<Value>'])
셀 수식을 얻으려면 다음을 수행하십시오.
cell = worksheet.acell('B1', value_render_option='FORMULA').value
# or
cell = worksheet.cell(1, 2, value_render_option='FORMULA').value
행 또는 열에서 모든 값 가져 오기
첫 번째 행에서 모든 값을 가져옵니다.
values_list = worksheet.row_values(1)
첫 번째 열에서 모든 값을 가져옵니다.
values_list = worksheet.col_values(1)
워크 시트의 모든 값을 목록 목록으로 가져 오기
list_of_lists = worksheet.get_all_values()
워크 시트의 모든 값을 목록 목록으로 가져와서 "특정단어"가 들어간 셀의 정보 찾기
list_of_lists = worksheet.get_all_values()
for ii in range(0,len(list_of_lists)):
for iii in range(0,len(list_of_lists[ii])):
if "값" in list_of_lists[ii][iii]:
print(list_of_lists[ii][iii])
cell = worksheet.find(list_of_lists[ii][iii])
print("셀의 행,열번호 : ", cell.row,cell.col)
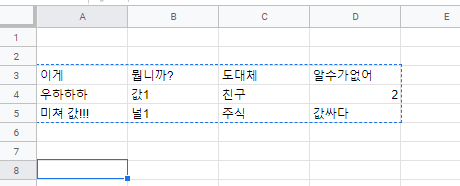
결과>>
값1
셀의 행,열번호 : 4 2 >> 4번째 행의 B열의 값은 값1
미쳐 값!!!
셀의 행,열번호 : 5 1 >> 5번째 행의 A열의 값은 미쳐 값!!!
값싸다
셀의 행,열번호 : 5 4 >> 5번째 행의 D열의 값은 값싸다
워크 시트의 모든 값을 사전 목록으로 가져 오기
list_of_dicts = worksheet.get_all_records()
세포 찾기
문자열과 일치하는 셀 찾기 :
cell = worksheet.find("Dough")
print("Found something at R%sC%s" % (cell.row, cell.col))
정규식과 일치하는 셀 찾기
amount_re = re.compile(r'(Big|Enormous) dough')
cell = worksheet.find(amount_re)
일치하는 모든 셀 찾기
문자열과 일치하는 모든 셀 찾기 :
cell_list = worksheet.findall("Rug store")
정규 표현식과 일치하는 모든 셀을 찾습니다.
criteria_re = re.compile(r'(Small|Room-tiering) rug')
cell_list = worksheet.findall(criteria_re)
셀 개체
각 셀에는 값과 좌표 속성이 있습니다.
value = cell.value
row_number = cell.row
column_number = cell.col
셀 업데이트
A1 표기법 사용 :
worksheet.update('B1', 'Bingo!')
또는 행 및 열 좌표 :
worksheet.update_cell(1, 2, 'Bingo!')
범위 업데이트
worksheet.update('A1:B2', [[1, 2], [3, 4]])
Pandas와 함께 gspread 사용
pandas 는 데이터 분석을위한 인기있는 라이브러리입니다. 시트에서 pandas DataFrame으로 데이터를 가져 오는 가장 간단한 방법은 다음을 사용하는 것입니다 get_all_records().
import pandas as pd
dataframe = pd.DataFrame(worksheet.get_all_records())
다음은 시트에 데이터 프레임을 쓰는 기본 예입니다. 함께 update()우리 dataframe의 값에 따르는 시트의 첫 번째 행으로 dataframe의 헤더를 입력 :
import pandas as pd
worksheet.update([dataframe.columns.values.tolist()] + dataframe.values.tolist())
고급 Pandas 사용 사례는 다음 라이브러리를 확인하세요.
NumPy와 함께 gspread 사용
NumPy 는 Python의 과학 컴퓨팅을위한 라이브러리입니다. 고성능 다차원 배열 작업을위한 도구를 제공합니다.
시트의 내용을 NumPy 배열로 읽습니다.
import numpy as np
array = np.array(worksheet.get_all_values())
위의 코드는 데이터가 시트의 첫 번째 행에서 시작한다고 가정합니다. 당신이 첫 번째 행 머리글 행이있는 경우 교체 필요 worksheet.get_all_values()로 worksheet.get_all_values()[1:].
시트에 NumPy 배열을 씁니다.
import numpy as np
array = np.array([[1, 2, 3], [4, 5, 6]])
# Write the array to worksheet starting from the A2 cell
worksheet.update('A2', array.tolist())
